Data mine your drives for sensitive data
In Confidential 1.2.31 we combined the search based on regular expressions, with the search in file content that we introduced in Confidential 1.2. So basically you can now tell Confidential to “scrape my disks and auto-tag everything that looks like credit number, an email address, invoice number, a name from a list or anything that can be describe by a regular expression”.
This feature can help you reaching GDPR compliance for your unstructured data: after deleting customers’ entries from your databases, this tool can help you find every bit of information about your customers that his contained on any file on your local and shared drives.
We wrote a guide and list of working regular expressions on our wiki.
- A quick example of what a RegEx can do for you is:
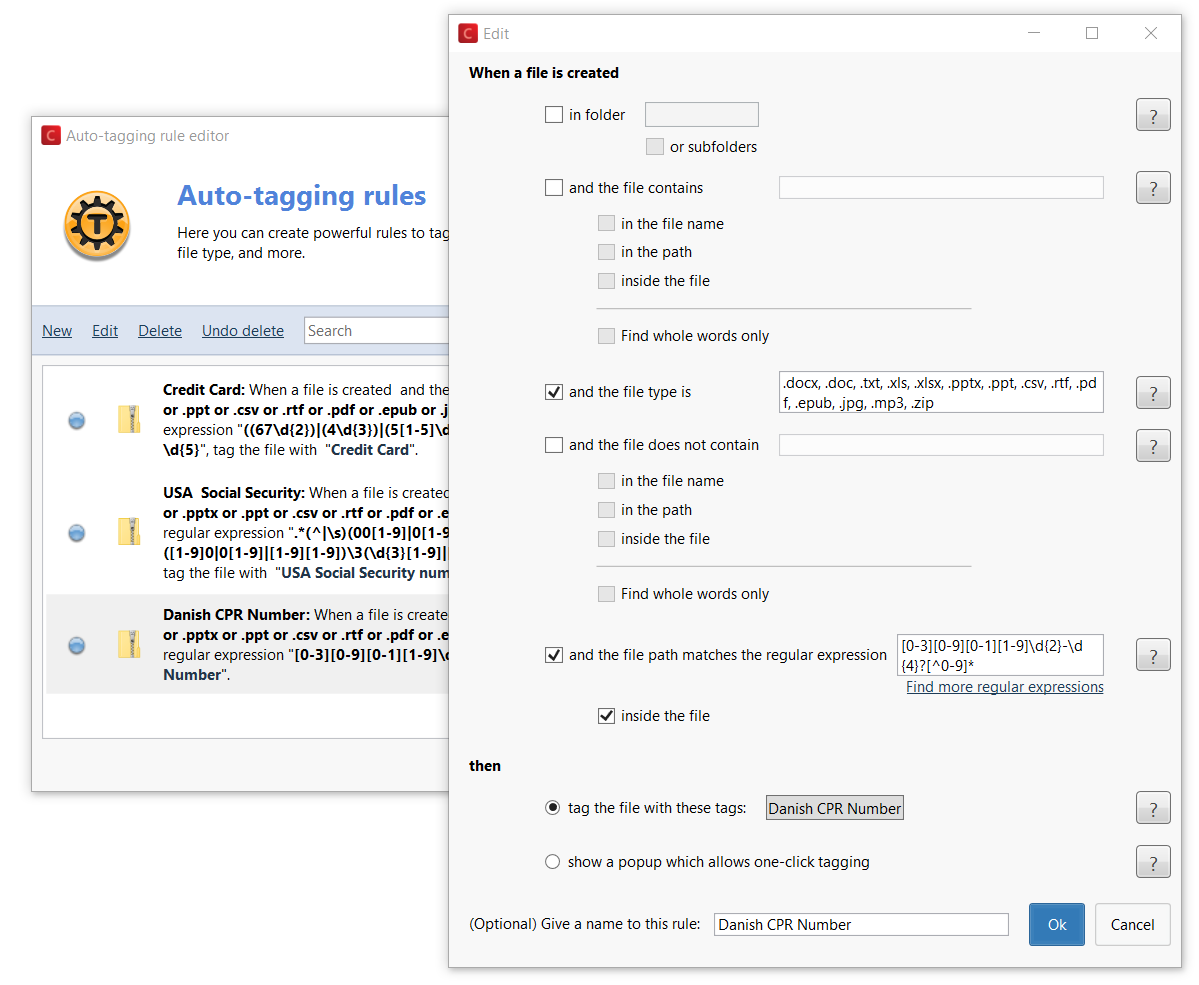
If your invoices look like “Inv2010-001” to “Inv2018-999“, you can setup one rule to get your invoices automatically tagged based on year, by matching the pattern “Inv(year)-###”. That rule would look like this: .*Inv(201\d)-\d{3}.* - You can now do proper data-mining on the tons of files on your drives and shared drives, telling Confidential for example to find and auto-tag “a social security number” or “any file that contains any email address” or “a phone number from a certain country or from a list or within a range” or “a city from a list”.
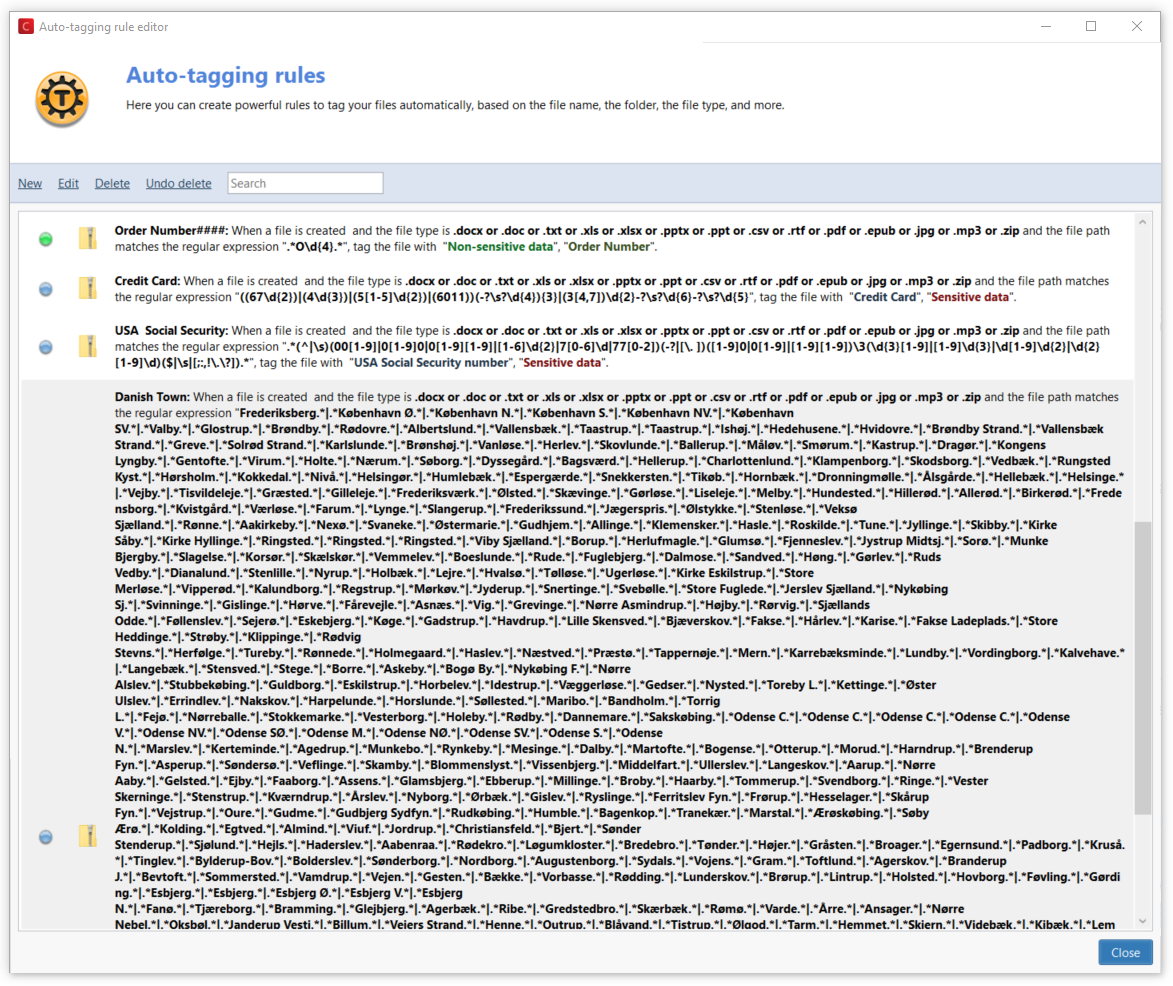
- You can easily create a rule containing a logical OR, that is a rule that matches, for example “Jon OR Jonathan” in the document (the rule would look like .*Jon.*|.*Jonathan.*). In the same way you can create a list that matches thousands of words (names, streets, cities etc.)
- Each rule can tag files with more tags and you can have multiple rules running at the same time… so this could result in tagging the same document with, for example, a customer id, a city name and invoicing year.
We are building sets of rules that you can import straight into your database from this page.
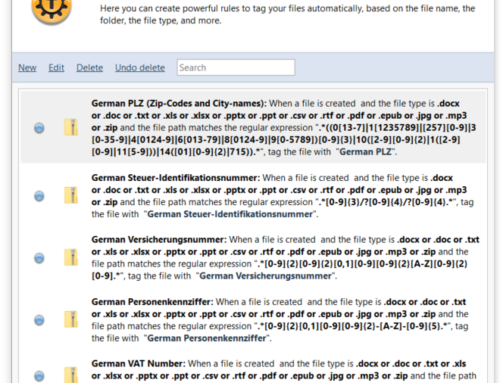
A couple of screenshots for what data-mining rules can look like 🙂
Data mining files containing social security numbers
Data mining files containing names or addresses from a list
Leave A Comment